Random Forest...
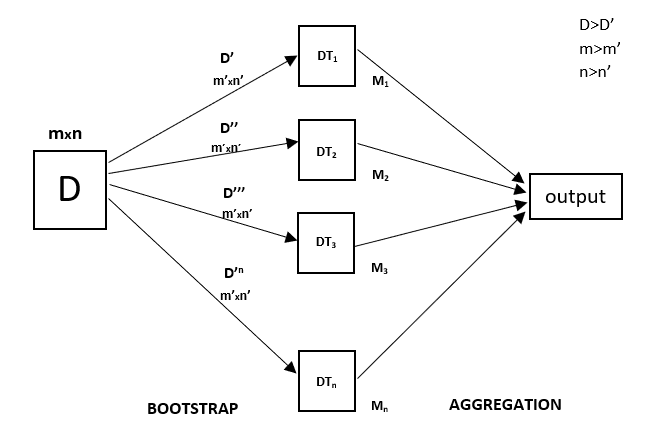
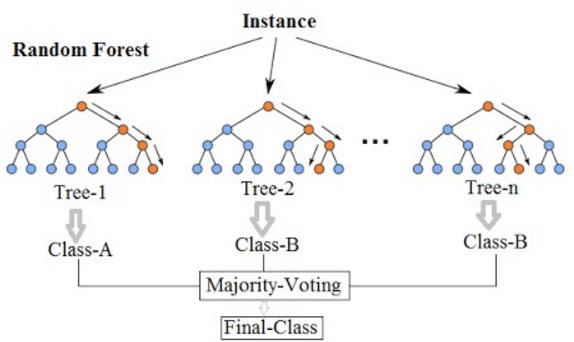
Random Forest is an ensemble technique capable of performing both regression and classification tasks with the use of multiple decision trees and a technique called Bootstrap and Aggregation , commonly known as bagging . The basic idea behind this is to combine multiple decision trees in determining the final output rather than relying on individual decision trees.
Ensembled algorithms are those which combines more than one algorithms of same or different kind for classifying objects.
Random Forest has multiple decision trees as base learning models. We randomly perform row sampling and feature sampling from the dataset forming sample datasets for every model. This part is called Bootstrap .
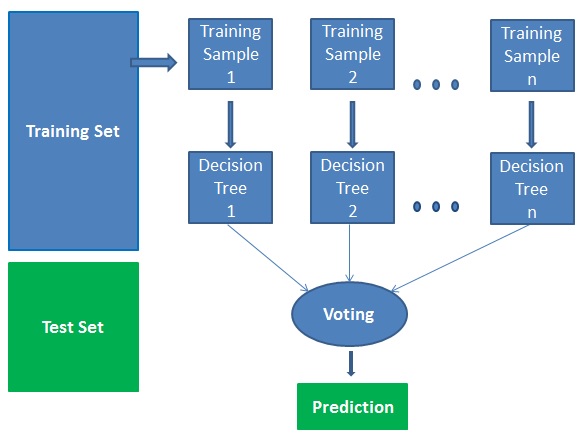
It technically is an ensemble method (based on the divide-and-conquer approach) of decision trees generated on a randomly split dataset. This collection of decision tree classifiers is also known as the forest. The individual decision trees are generated using an attribute selection indicator such as information gain, gain ratio, and Gini index for each attribute. Each tree depends on an independent random sample.
In a classification problem, each tree votes and the most popular class is chosen as the final result. In the case of regression, the average of all the tree outputs is considered as the final result. It is simpler and more powerful compared to the other non-linear classification algorithms.
Types of Random Forest models:
1. Random Forest Prediction for a classification problem: f(x) = majority vote of all predicted classes over B trees
2. Random Forest Prediction for a regression problem: f(x) = sum of all sub-tree predictions divided over B trees
Finding important features:
Random forests also offers a good feature selection indicator. Scikit-learn provides an extra variable with the model, which shows the relative importance or contribution of each feature in the prediction. It automatically computes the relevance score of each feature in the training phase. Then it scales the relevance down so that the sum of all scores is 1.
This score will help you choose the most important features and drop the least important ones for model building.
Random forest uses gini importance or mean decrease in impurity (MDI) to calculate the importance of each feature. Gini importance is also known as the total decrease in node impurity. This is how much the model fit or accuracy decreases when you drop a variable. The larger the decrease, the more significant the variable is. Here, the mean decrease is a significant parameter for variable selection. The Gini index can describe the overall explanatory power of the variables.
Random Forests vs Decision Trees :
1. Random forests is a set of multiple decision trees.
2. Deep decision trees may suffer from overfitting, but random forests prevents overfitting by creating trees on random subsets.
3. Decision trees are computationally faster.
4. Random forests is difficult to interpret, while a decision tree is easily interpretable and can be converted to rules.
Tuning parameters used in Random Forest are :
1. n_estimators : Number of trees in forest. Default is 10.
2. criterion: “gini” or “entropy” same as decision tree classifier.
3. min_samples_split: minimum number of working set size at node required to split. Default is 2.
Features and Advantages of Random Forest :
1. It is one of the most accurate learning algorithms available. For many data sets, it produces a highly accurate classifier.
2. It runs efficiently on large databases.
3. It can handle thousands of input variables without variable deletion.
4. It gives estimates of what variables that are important in the classification.
5. It generates an internal unbiased estimate of the generalization error as the forest building progresses.
6. It has an effective method for estimating missing data and maintains accuracy when a large proportion of the data are missing.
Disadvantages:
1. Random forests is slow in generating predictions because it has multiple decision trees. Whenever it makes a prediction, all the trees in the forest have to make a prediction for the same given input and then perform voting on it. This whole process is time-consuming.
2. The model is difficult to interpret compared to a decision tree, where you can easily make a decision by following the path in the tree.
3. Random forests have been observed to overfit for some datasets with noisy classification/regression tasks.
4. For data including categorical variables with different number of levels, random forests are biased in favor of those attributes with more levels. Therefore, the variable importance scores from random forest are not reliable for this type of data.
Learn More
Learn More
Learn More
Learn More
Learn More