Ensemable Learning Techniques...
Ensemable Learning Methods :
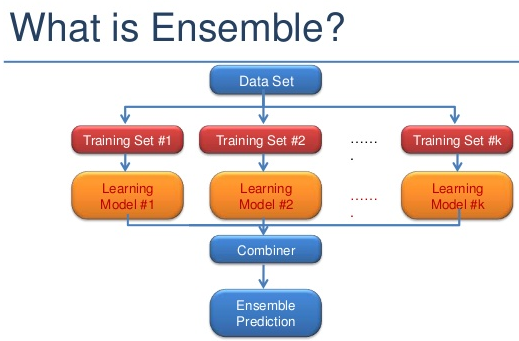
Ensemble learning is a machine learning paradigm where multiple models (often called “weak learners” ) are trained to solve the same problem and combined to get better results. The main hypothesis is that when weak models are correctly combined we can obtain more accurate and robust models.
A low bias and a low variance , although they most often vary in opposite directions, are the two most fundamental features expected for a model. Indeed, to be able to solve a problem, we want our model to have enough degrees of freedom to resolve the underlying complexity of the data we are working with, but we also want it to have not too much degrees of freedom to avoid high variance and be more robust. This is the well known bias-variance tradeoff . The following picture shows the Bias-varience tradeoff.
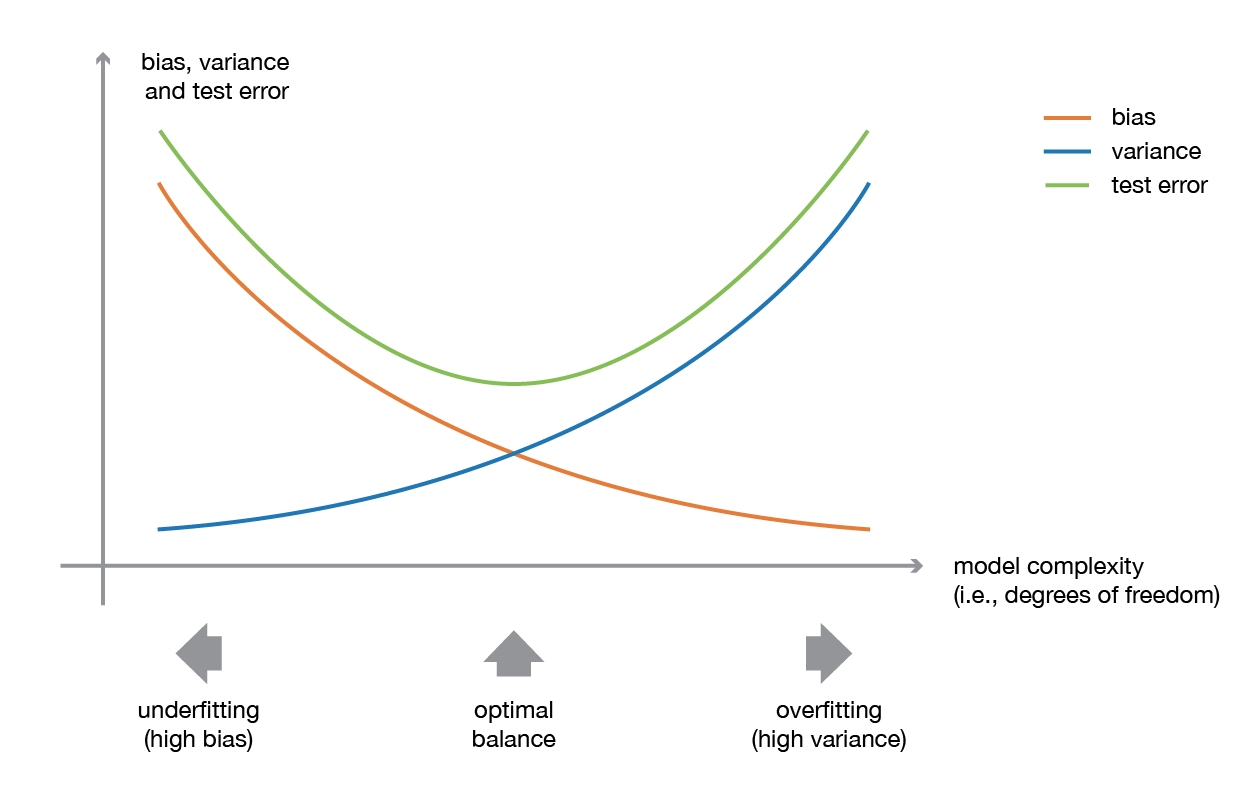
The idea of ensemble methods is to try reducing bias and/or variance of such weak learners by combining several of them together in order to create a strong learner (or ensemble model) that achieves better performances.
Introduction to Boosting :
“Alone we can do so little and together we can do much” — Helen Keller
Bagging (stands for Bootstrap Aggregating): It is an approach where you take random samples of data, build learning algorithms and take simple means to find bagging probabilities. Bagging , that often considers homogeneous weak learners, learns them independently from each other in parallel and combines them following some kind of deterministic averaging process.
Boosting: Boosting is similar, however the selection of sample is made more intelligently. We subsequently give more and more weight to hard and classify observations. Boosting , that often considers homogeneous weak learners, learns them sequentially in a very adaptative way and combines them following a deterministic strategy.
Boosting is an ensemble learning technique that uses a set of Machine Learning algorithms to convert weak learner to strong learners in order to increase the accuracy of the model.

Stacking , that often considers heterogeneous weak learners, learns them in parallel and combines them by training a meta-model to output a prediction based on the different weak models predictions.
We can say that bagging will mainly focus at getting an ensemble model with less variance than its components whereas boosting and stacking will mainly try to produce strong models less biased than their components (even if variance can also be reduced).
Ensemble is a machine learning concept in which multiple models are trained using the same learning algorithm. Bagging is a way to decrease the variance in the prediction by generating additional data for training from dataset using combinations with repetitions to produce multi-sets of the original data. Boosting is an iterative technique which adjusts the weight of an observation based on the last classification. If an observation was classified incorrectly, it tries to increase the weight of this observation. Boosting in general builds strong predictive models. Ensemble methods combine several decision trees classifiers to produce better predictive performance than a single decision tree classifier. The main principle behind the ensemble model is that a group of weak learners come together to form a strong learner, thus increasing the accuracy of the model.
Ensemble learning is a method that is used to enhance the performance of Machine Learning model by combining several learners. When compared to a single model, this type of learning builds models with improved efficiency and accuracy. This is exactly why ensemble methods are used to win market leading competitions such as the Netflix recommendation competition, Kaggle competitions and so on.
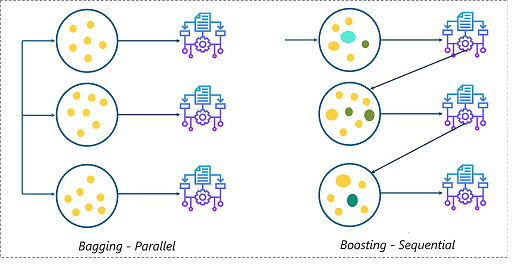
Boosting vs Bagging : Ensemble learning can be performed in two ways:
Sequential ensemble, popularly known as boosting, here the weak learners are sequentially produced during the training phase. The performance of the model is improved by assigning a higher weightage to the previous, incorrectly classified samples. An example of boosting is the AdaBoost algorithm.
Parallel ensemble, popularly known as bagging, here the weak learners are produced parallelly during the training phase. The performance of the model can be increased by parallelly training a number of weak learners on bootstrapped data sets. An example of bagging is the Random Forest algorithm.
There are multiple boosting algorithms like AdaBoost, Gradient Boosting, XGBoost, etc. Every algorithm has its own underlying mathematics and a slight variation is observed while applying them.
AdaBoost (Adaptive Boosting) :
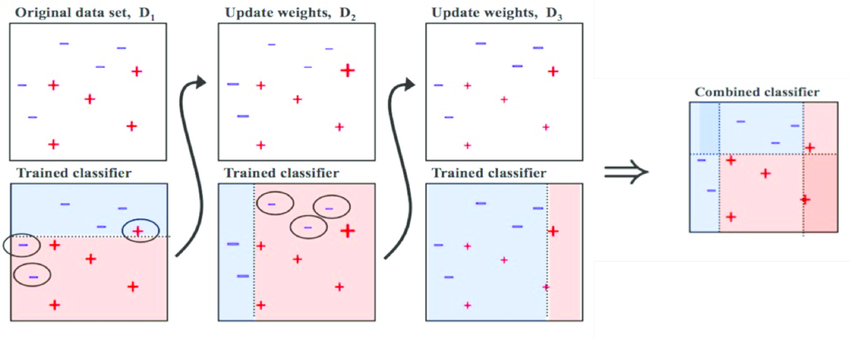
AdaBoost combines multiple weak learners into a single strong learner. The weak learners in AdaBoost are decision trees with a single split, called decision stumps . When AdaBoost creates its first decision stump, all observations are weighted equally. To correct the previous error, the observations that were incorrectly classified now carry more weight than the observations that were correctly classified. AdaBoost algorithms can be used for both classification and regression problem.
The diagram shown below, aptly explains AdaBoost.
Advantages of AdaBoost :
1. Can be used with many different classifiers
2. Improves classification accuracy
3. Commonly used in many areas
4. Simple to implement
5. Does feature selection resulting in relatively simple classifier
6. Not prone to overfitting
7. Fairly good generalization
Disadvantages of AdaBoost :
1. The drawback of AdaBoost is that it is easily defeated by noisy data, the efficiency of the algorithm is highly affected by outliers as the algorithm tries to fit every point perfectly.
2. Even though this algorithm tries to fit every point, it doesn’t overfit.
3. Suboptimal solution
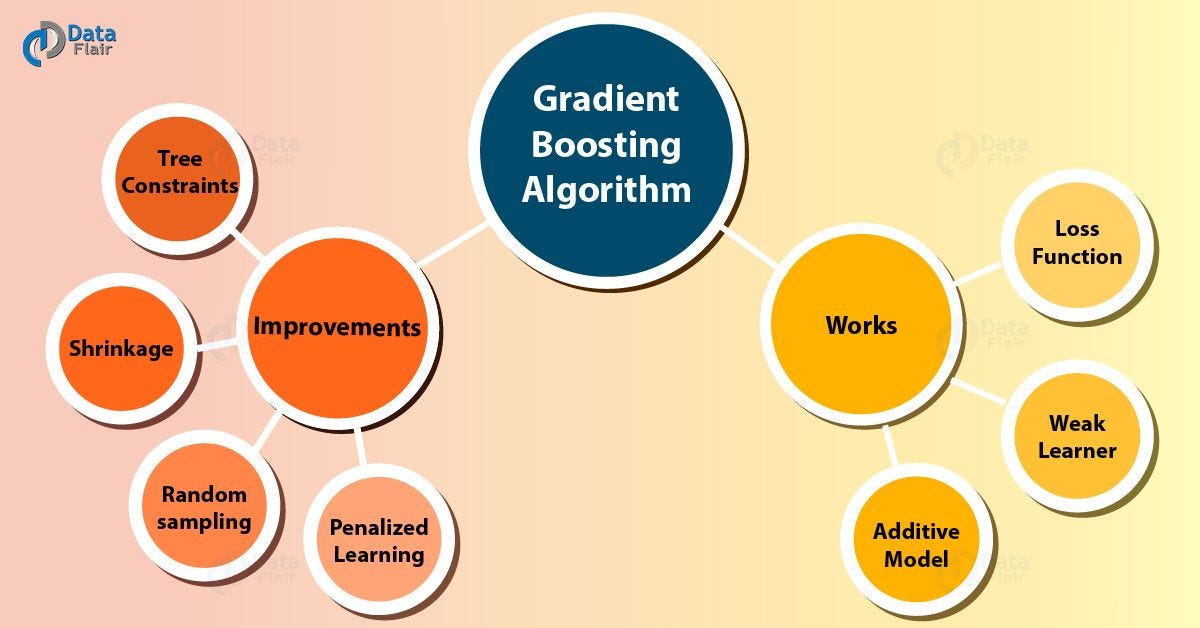
Gradient Boosting :
Just like AdaBoost, Gradient Boosting works by sequentially adding predictors to an ensemble, each one correcting its predecessor. However, instead of changing the weights for every incorrect classified observation at every iteration like AdaBoost, Gradient Boosting method tries to fit the new predictor to the residual errors made by the previous predictor. Gradient boosting is a machine learning technique for regression and classification problems, which produces a prediction model in the form of an ensemble of weak prediction models, typically decision trees. The objective of any supervised learning algorithm is to define a loss function and minimize it.
In Gradient Boosting Machine (GBM), we take up a weak learner and at each step, we add another weak learner to increase the performance and build a strong learner. This reduces the loss of the loss function. We iteratively add each model and compute the loss. The loss represents the error residuals (the difference between actual value and predicted value) and using this loss value the predictions are updated to minimise the residuals.
Gradient Boosting is also based on sequential ensemble learning. Here the base learners are generated sequentially in such a way that the present base learner is always more effective than the previous one, i.e. the overall model improves sequentially with each iteration.
The difference in this type of boosting is that the weights for misclassified outcomes are not incremented, instead, Gradient Boosting method tries to optimize the loss function of the previous learner by adding a new model that adds weak learners in order to reduce the loss function.
The main idea here is to overcome the errors in the previous learner’s predictions. This type of boosting has three main components: 1. Loss function that needs to be ameliorated.
2. Weak learner for computing predictions and forming strong learners.
3. An Additive Model that will regularize the loss function.
GBM is the most widely used algorithm.
Advantages of GBM :
1. Often provides predictive accuracy that cannot be beat.
2. Lots of flexibility — can optimize on different loss functions and provides several hyper-parameter tuning options that make the function fit very flexible.
3. No data pre-processing required — often works great with categorical and numerical values as is.
4. Handles missing data — imputation not required.
Disadvantages of GBM :
1. GBMs will continue improving to minimize all errors. This can overemphasize outliers and cause overfitting. Must use cross-validation to neutralize.
2. Computationally expensive — GBMs often require many trees (>1000) which can be time and memory exhaustive.
3. The high flexibility results in many parameters that interact and influence heavily the behavior of the approach (number of iterations, tree depth, regularization parameters, etc.). This requires a large grid search during tuning.
4. Less interpretable although this is easily addressed with various tools (variable importance, partial dependence plots, LIME, etc.).
XGBoost :
XGBoost stands for eXtreme Gradient Boosting and is another faster version of boosting learner. XGBoost is an implementation of gradient boosted decision trees designed for peed and performance. Gradient boosting machines are generally very slow in implementation because of sequential model training. Hence, they are not very scalable. Thus, XGBoost is focused on computational speed and model performance.
The main aim of this algorithm is to increase the speed and efficiency of computation. The Gradient Descent Boosting algorithm computes the output at a slower rate since they sequentially analyze the data set, therefore XGBoost is used to boost or extremely boost the performance of the model .
XGBoost provides:
1. Parallelization of tree construction using all of your CPU cores during training.
2. Distributed Computing for training very large models using a cluster of machines.
3. Out-of-Core Computing for very large datasets that don’t fit into memory.
4. Cache Optimization of data structures and algorithm to make the best use of hardware.
5. XGBoost is similar to gradient boosting algorithm but it has a few tricks up its sleeve which makes it stand out from the rest.

Features of XGBoost are :
1. Clever Penalisation of Trees
2. A Proportional shrinking of leaf nodes
3. Newton Boosting
4. Extra Randomisation Parameter
XGBoost is faster than gradient boosting but gradient boosting has a wide range of application.
Advantages of XGBoost :
1. Regularization : Standard GBM implementation has no regularization like XGBoost, therefore it also helps to reduce overfitting. Thats why, XGBoost is also known as regularized boosting technique.
2. Parallel Processing : XGBoost implements parallel processing and is blazingly faster as compared to GBM. XGBoost also supports implementation on Hadoop.
3. High Flexibility : XGBoost allow users to define custom optimization objectives and evaluation criteria.
4. Handling Missing Values : XGBoost has an in-built routine to handle missing values.
5. Tree Pruning : XGBoost make splits upto the max_depth specified and then start pruning the tree backwards and remove splits beyond which there is no positive gain.
6. Built-in Cross-Validation : XGBoost allows user to run a cross-validation at each iteration of the boosting process and thus it is easy to get the exact optimum number of boosting iterations in a single run.
Ensemble methods are learning models that achieve performance by combining the opinions of multiple learners. Typically, an ensemble model is a supervised learning technique for combining multiple weak learners or models to produce a strong learner with the concept of Bagging and Boosting for data sampling. Ensemble method is a combination of multiple models, that helps to improve the generalization errors which might not be handled by a single modeling approach.
Learn More
Learn More